 打印本文
打印本文  关闭窗口
关闭窗口 海明校验码
这是由Richard Hamming于1950年提出、目前还被广泛采用的一种很有效的校验方法,是只要增加少数几个校验位,就能检测出二位同时出错、亦能检测出一位出错并能自动恢复该出错位的正确值的有效手段,后者被称为自动纠错。它的实现原理,是在k个数据位之外加上r个校验位,从而形成一个k+r位的新的码字,使新的码字的码距比较均匀地拉大。把数据的每一个二进制位分配在几个不同的偶校验位的组合中,当某一位出错后,就会引起相关的几个校验位的值发生变化,这不但可以发现出错,还能指出是哪一位出错,为进一步自动纠错提供了依据。
假设为k个数据位设置r个校验位,则校验位能表示2r个状态,可用其中的一个状态指出 "没有发生错误",用其余的2 r -1个状态指出有错误发生在某一位,包括k个数据位和r个校验位,因此校验位的位数应满足如下关系:
2r ≥ k + r + 1 (2.7)
如要能检出与自动校正一位错,并能同时发现两位错,此时校验位的位数r和数据位的位数k应满足下述关系:
2r-1 ≥ k + r (2.8)
按上述不等式,可计算出数据位k与校验位r的对应关系,如表2.2所示。
|
K值 |
最小的r值 |
|
3-4 |
4 |
|
5-10 |
5 |
|
11-25 |
6 |
|
26-56 |
7 |
|
57-119 |
8 |
设计海明码编码的关键技术,是合理地把每个数据位分配到r个校验组中,以确保能发现码字中任何一位出错;若要实现纠错,还要求能指出是哪一位出错,对出错位求反则得到该位的正确值。例如,当数据位为3位(用D3 D2 D1表示)时,检验位应为4位(用P4 P3 P2 P1表示)。可通过表2.3表示的关系,完成把每个数据位划分在形成不同校验位的偶校验值的逻辑表达式中。
表2.3 校验位与数据位的对应关系
在P1、P2、P3、P4竖列相应行分别填1,
在该4列的低3横行其它位置分别填0,
在最顶横行的每个尚空位置都分别填1。
若只看低3横行,右4竖列的3个bit的组合值分别为十进制的1、2、4、0,则分配 D1 D2 D3列的组合值为3 5 6,保证低3横行各竖列的编码值各不相同。
表中D3 D2 D1为三位数据位,P4 P3 P2 P1为四位校验位。其中低三位中的每一个校验位P3 P2 P1的值,都是用三个数据位中不同的几位通过偶校验运算规则计算出来的。其对应关系是:对Pi(i的取值为1~3),总是用处在Pi取值为1的行中的、用1标记出来的数据位计算该Pi的值。最高一个校验位P4,被称为总校验位,它的值,是通过对全部三个数据位和其它全部校验位(不含P4本身)执行偶校验计算求得的。
形成各校验位的值的过程叫做编码,按刚说明的规则,4个校验位所用的编码方程为:

由多个数据位和多个校验位组成的一个码字,将作为一个数据单位处理,例如被写入内存或被传送走。之后,在执行内存读操作或在数据接收端,则可以对得到的码字,通过偶校验来检查其合法性,通常称该操作过程为译码,所用的译码方程为: 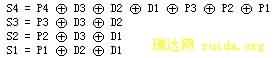
译码方程和编码方程的对应关系很简单。译码方程,是用一个校验码和形成这个校验码的编码方程执行异或,实际上是又一次执行偶校验运算。通过检查四个S的结果,可以实现检错纠错的的目的。实际情况是,当译码求出来的S4、S3、S2、S1的得值与表2.3中的那一列的值相同,就说明是哪一位出错;故人们又称表2.3为出错模式表。若出错的是数据位,对其求反则实现纠错;若出错的是校验位则不必理睬。举例如下:
任何一位(含数据位、校验位)均不错,则四个S都应为0值;
任何单独一位数据位出错,四个S中会有三个为1;如D3错,则S4 S3 S2 S1为1110。
若单独一位校验位出错,四个S中会有一个或两个为1;如P1错,S4 S3 S2 S1为1001,如P4错,S4 S3 S2 S1为1000。
任何两位(含数据位、校验位)同时出错,S4一定为0,而另外三个S位一定不全为0,此时只知道是两位同时出错,但不能确定是哪两位出错,故已无法纠错。如D1、 P2出错,会使S4 S3 S2 S1为0001。请注意,S4的作用在于区分是奇数位出错还是偶数位出错,S4为1是奇数位错,为0是无错或偶数位错。这不仅为发现两位错所必需,也是为确保能发现并改正一位错所必需的。若不设置S4,某种两位出错对几个S的影响与单独另一位出错可能是一样的(不必花费精力推敲),此时若不加以区分,简单地按一位出错自动完成纠错处理反而会帮倒忙。
打印本文 关闭窗口