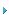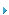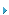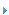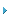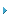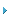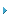本文将向您介绍一款采用光纤通道协议实现RAID控制器的系统设计方案。我们将重点讨论如何使用安捷伦Tachyon 4Gb/s 4端口光纤通道协议IC,把多个磁盘通道加入在一个提供RAID应用的计算系统中,并对使用RAID存储技术的整个系统进行简单介绍(包括光纤通道拓扑及选项、FC终端、磁盘通道和处理器功能)。
RAID系统架构概述
数据存储的应用越来越广泛。过去的单一设备现在容纳或产生大量的数字信息。海量数据时代的到来加速了人们对信息安全存储的需求。光阴荏苒,人们保存了大量的数据,但是重新获得丢失的数据却要耗资巨大。为此,人们部署了可*的数据存取系统来保存或存储数据。随着保护数据安全呼声的高涨,对RAID解决方案的需求也日益增加。RAID解决方案提供有多种有助于提高数据检索成功率的选择方案。尽管RAID技术现在已可以应用于实现可*检索所需的任何数字存储介质上,当前人们还是普遍把数据存储在物理介质上。
在一个实施RAID技术的完备系统中,需要考虑下列事项:
* 带一个或多个CPU的控制处理机。
* 需要将一些磁盘与控制处理机相连接。通常采用专门用于附加驱动器的特殊协议实现磁盘连接。目前,有好几种流行的磁盘协议。这里我们将重点介绍在大多数高端存储阵列设计中使用的光纤通道协议。
* 驱动器和处理器间无法直接实现高效连接。为此,人们使用了协议转换器为一个接口上的处理器提供API,并实现与另一个接口上驱动器的连接。
图1:RAID控制器功能最简单架构的典型系统示例
图1为典型系统示例,其中包括四个CPU,一个由内存控制器和接口设备组成的处理器组(Processor Complex)、一个协议控制器和多个光纤通道链路组成的阵列。对磁盘控制器架构的多样性和利弊,本文不作讨论。图1所示系统为最简单的通用架构,我们将用它来介绍RAID控制器的一般功能。
RAID概述
RAID实施方案这一概念并不仅仅包括以后检索所需的储存数据,它还涉及到采用下文介绍的一级或多机RAID架构。
RAID-0:数据分割(Striping)。数据分割不能增加系统安全性,但可以提高系统性能。一个文件被存储在多个驱动器上。文件被分成若干块,并被依次写入连续的磁盘中,这样就可以分摊单个驱动器的写反应时间并使多个写操作重迭进行。
RAID-1:磁盘镜像(Mirroring)。将一个磁盘上的所有数据完全复制到另一个磁盘中。这需要将数据写入不同的磁盘中,涉及到两个单独的写操作。这两个磁盘无主次之分,一个磁盘是另一个磁盘100%的备份。已完成的写操作,必须是已同时在两个磁盘上完成了同样的写操作。如果一个磁盘故障,与之镜像的磁盘保持正常操作,不会造成中断。RAID-1提供了较好的管理能力,而且在正常操作或系统恢复时不需要占用太多的CPU。但这种方式成本很大:磁盘上需要保护的每千兆字节都会需要一个完全一模一样的千兆字节。换句话说,RAID-1所需要的磁盘空间是无保护磁盘空间的两倍。
RAID-2:汉明码纠错(Hamming code error correction)。与ECC内存一样,RAID-2也使用了汉明码方法校验磁盘数据的正确性。
RAID-3、RAID-4和RAID-5都使用了不同的奇偶校验方法。与RAID-1完全复制数据不同,这些等级的RAID通过添加一个附加磁盘将数据分散在几个磁盘上。附加磁盘上的数据是用其它磁盘的数据计算出来(使用Boolean XORs)。当磁盘组中任一个丢失时,可以用磁盘组中其它磁盘上的数据通过计算来恢复丢失的数据。由于这几种方法不需要RAID-1 100%磁盘备份的费用,因此它们所需成本比RAID-1要低。然而,由于磁盘上的数据是计算出来的,磁盘丢失后会影响与写操作和数据恢复相关的性能。
RAID-3:虚拟磁盘块(Virtual disk blocks)。RAID 3会把数据写入操作分散到RAID阵列中的所有磁盘上进行(数据分割)。因为每次写操作要接触每个磁盘,阵列同时只能写入一块数据,因此导致整个RAID系统性能下降。RAID-3的性能因写操作性质的不同而不同:写入少量数据时因需要所有的磁盘工作,性能较差,而在写入大量数据时性能较好。
RAID-4:专用奇偶盘(Dedicated parity disk)。在RAID-4阵列中,有一组数据盘,通常是4~5个数据盘(可以有更多数据盘,但会大大影响性能)和一个专门用来管理其它磁盘上数据奇偶性的特殊磁盘。因为每次写操作都需要访问奇偶盘,奇偶盘成了系统性能的瓶颈,降低了整个阵列中所有写操作的速度。
RAID-5:磁盘分割(Striped parity)。RAID-5实际上与RAID-4一样,唯一不同的是:在RAID-4中,所有奇偶校验信息位于一个单一磁盘上,而在RAID-5中,对奇偶校验信息进行了分割,将其存放在阵列中各个磁盘上。这种共享可以均衡并减少RAID-4方法的性能影响。在常用的RAID-5软件实施方案中,由于写操作占用了15%以上的磁盘空间,系统速度会变得很慢,令人难以接受。
要实施任意RAID组合,需要考虑几个功能。在实施0级以上的RAID方案时,通常要连接多个磁盘。为了实现数据分割、镜像和奇偶校验,采用了多种磁盘存取方式或操作。例如,为了实现RAID-1,需要连续向两个驱动器写入数据。磁盘的读或写操作通常被称之为磁盘输入/输出(I/O)。这可以是可与一个或多个驱动器实现通信的任意协议。这个功能可通过系统中一个或多个处理器上运行的软件实现。方法是在通过协议控制器API实现RAID技术和进行通信时,实现高级磁盘写入功能。
最好使用一个可以管理多个磁盘通道的协议控制器,使处理控制机可以在RAID应用中和系统管理功能上工作。对于部署连接状态和多个驱动器通道的光纤通道等复杂协议而言,通常使用类似于Tachyon系列产品的高端控制器为系统提供最高等级的性能。
Tachyon架构
Tachyon光纤通道协议控制器系列产品采用了1Gb、2Gb和4Gb 光纤通道链路,并根据不同设备通过PCI、PCI-X或PCI Express接口与系统相连。
尽管不论是光纤通道技术,还是系统总线互连技术都取得了重大进展,Tachyon协议引擎系统架构却是随着半导体工艺技术的发展而拓展。这一架构以FSM(Finite State Machine)设计为基础。在FSM设计中,采用了众多独立状态机,这些状态机并行运行,因此可以获得比固件或软件解决方案更高的性能。随着频率增加,Tachyon的性能也相应提高,而在基于固件的解决方案中,电路频率并不会直接改善算法的性能。
Tachyon架构支持入局和出局数据通路独立和同步运行,因此可以在光纤通道链路全速率下实现全双工操作。此外,由于在数据移动的同时可以同步处理I/O操作的控制请求,Tachyon架构还可以实现数据移动设备的最佳利用。
FSM的性能与时钟频率密切相关。FSM设计不但可以决定每个时钟周期,而且和嵌入式微处理器一样在发布指令和数据找取时对内存存取速度没有依赖性。除了随链路性能工艺技术的发展而升级,Tachyon还利用系统接口总线的技术改进来增加每秒I/O性能。
PCI Express的适用性
过去,双向系统总线接口(如PCI和PCI-X)共享资源限制了Tachyon架构中的全双工功能。Tachyon产品中两个独立的数据移动设备争相占用PCI或PCI-X系统接口。
图2:用PCI Express提供的独立Ingress和Egress
通路对PCI和PCI-X的双向总线系统接口进行对比。
由于Express Ingress数据通路与Tachyon 出局数据通路以及
Express Egress数据通路与Tachyon入局数据通路的结合使用数据可以同时双向自由传输。
带有独立Ingress和Egress数据通路链接的PCI Express非常适用于Tachyon架构。由于Express Ingress数据通路与Tachyon出局数据通路以及Express Egress数据通路与Tachyon入局数据通路的结合使用,数据可以同时双向自由传输,这与Tachyon架构的初衷一致。
从一个双向系统总线转变为一对单向链路还消除了与关联交易相关的丢失总线周期,此时,在总线中有一个等待返回数据的请求(即寄存器读)。此外,由于PCI Express是一个串行链路技术,请求可以用管线技术处理。大量经过管线技术处理的请求可以较好地利用目标设备的性能。
因为PCI Express与Tachyon光纤通道控制器一样,可以提供成对的双向串行链路,所以可以用每秒每个链路方向传递的字节数来表示带宽连接性能。一路(lane)PCI Express由两个速率为2.5Gb/s的单向串行链路组成,编解码后每个方向每秒可以处理250Mbytes。应用PCI-E技术的Tachyon系列产品(QX4和QX2)可以配置为1路、4路或8路PCI Express,所以可以提供高达4Gbytes的互传带宽或单向2Gbytes的带宽。表1所示为Tachyon系列产品的带宽需求与PCI Express性能的匹配情况:

表1:Tachyon带宽要求与PCI Express性能的匹配情况
从上表可以看出,PCI Express接口的利用率达到了80%时,8路PCI Express理论上讲可以支持QX4(4个4Gb光纤通道链路)全链路速率下的所有4个功能。支持多个4路Express链路的PCI Express根联合体(root complex)可以与两个QX2设备相连(每个设备4路PCI Express)并可以在所有8个端口上获得2Gb/s的全光纤通道链路速率,利用率达到了80%。
正是由于PCI Express的串行链路属性与Express的灵活性,PCI Express成为适用于Tachyon光纤通道协议控制器系列产品的最佳系统接口总线。PCI Express协议的向后兼容性因为可以实现驱动器兼容而简化了从PCI或PCI-X系统接口总线转成PCI Express的决策过程。
使用像Tachyon这样高度集成的设备,用现成的组件标准就可以构建高性能的RAID系统。利用处理器的可变性和内存设计,只要利用普通的系统软件投资,就可以调整目标系统应用解决方案的性能,使其从一个低端的SMB转变为高端数据中心阵列。
当前PCI Express的性能
在上表中介绍了PCI Express总线的原始位率性能。其中,没有考虑与PCI Express相关的开销。PCI Express通信主要由处理层数据包(TLP)组成。每个处理层数据包(TLP)包含相关数据以及文件头和其它顺序跟踪/检错信息。除了处理层数据包(TLP)外,还有数据链路层数据包(DLLP)。数据链路层数据包(DLLP)主要用于ACK/NAK协议以及流控制机制(Flow Control Mechanisms)。此外,还有物理层数据包(PLP),但物理层数据包(PLP)主要用于低级功能和不良路径操作,如链路培训(link training)和省电模式。
每个处理层数据包(TLP)系统开销较大。它由文件头、CRC和其它帧信息组成。由于每个处理层数据包(TLP)有固定的系统开销,较大的处理层数据包(TLP)可以较好地利用系统总线。如果假设与处理层数据包(TLP)的数量相比,数据链路层数据包(DLLP)和物理层数据包(PLP)的数量可以忽略不计,我们可以用处理层数据包(TLP)的大小计算PCI-Express的最大理论带宽。在表2中,我们对用PCI Express理论带宽所测得的QX4性能与即将可用(2005年1月)的PCI Express根联合体(Root Complex)支持的各种处理层数据包(TLP)进行了对比。

表2:测得的QX4性能与各种不同大小处理层数据包的PCI-Express理论带宽之比较
在表2中,假设没有与FCP通信、Tachyon数据结构或Tachyon寄存器存取相关的开销。这些理论数值还假设PCI-Express根联合体的等待时间为零。所测得的QX4 1.1数值包括FCP 流量开销、Tachyon数据结构和寄存器存取开销以及PCI Express的等待时间。
在半双工通信配置下(顶部的只向一个方向传输),链路控制数据链路层数据包(DLLP)被发送到数据处理层数据包(TLP)的相反方向,因此不会降低系统性能。引入全双工后,流程控制数据链路层数据包(DLLP)和数据处理层数据包可以共享相同的PCI Express 单工通道;任何一个流程控制数据链路层数据包(DLLP)都会引起数据处理层数据包(TLP)的传输延迟。再次重申,所有理论带宽都假设数据链路层数据包(DLLP)和物理层数据包(PLP)的影响忽略不计。
上述有关带宽的讨论,阐述了如何根据4Gb光纤通道设备对PCI Express进行升级。并用一个设备在一秒钟内可以完成的512字节I/0这一数值对IOPS(每秒I/O)进行了定义。IOPS测量值也可随着PCI Express的升级而升级。
我们使用当前可用的PCI Express芯片集和单个安捷伦QX4,发现IOPS的数值超过1.3 MIOPS(图3)。随着处理器速度变快以及可以支持更大的处理层数据包(TLP),预计我们可以看到更好的性能。
图3:使用一个安捷伦QX4 Tachyon光纤通道控制器IC
和目前可用的PCI Express芯片集所获得的I/O大小与按顺序读取IOPS之对比
|
|
|